

#3: Inteligencia Artificial. Kit de supervivencia
#3: Inteligencia Artificial. Kit de supervivencia
Primer post dedicado a la IA. Incluye definiciones y conceptos básicos para entender la realidad que nos viene.

Hola soy Francisco Fernández @franferparra, Director de Transformación Digital y esta es mi newsletter dedicada a entender la tecnología a través de la simplificación. Porque no es lo mismo Simple que Fácil!
Este post es el primero de muchos, no necesariamente en un orden secuencial, dedicado a la Inteligencia Artificial (IA). Al final de este post podéis encontrar una infografía resumen con lo básico de la IA.
Justamente esta semana Pedro Sánchez ha anunciado que va a destinar 600 Millones de euros al desarrollo de la IA en España, así que este post me viene perfecto para hacer un kit de primeros auxilios para entender la Inteligencia Artificial.

De Siri a Terminator
El término Inteligencia Artificial (IA) genera mucha confusión principalmente por tres factores:
La Ciencia Ficción en películas y series como Terminator nos han dado una imagen de que la IA son robots con aspecto humanoide.
Amplitud del término. La Inteligencia Artificial cubre un espectro tan amplio de aplicaciones, desde coches autónomos a recomendadores de películas, que es difícil entender los conceptos básicos y sus componentes.
Está tan presente en nuestro día a día que la hemos “normalizado” sin ser conscientes de que detrás de Siri hay mucha IA.
¿Qué es la Inteligencia Artificial?
El término IA apareció por primera vez en 1955 acuñado por John McCarthy y decía algo así como que “It is the science and engineering of making intelligent machines”, vamos que no nos aporta mucho…
Después de McCarthy han habido muchos autores que han dado sus propias deficiniones pero podemos resumirlo como:
Una rama de la ciencia computacional que se encarga de simular comportamientos inteligentes.
La capacidad de las máquinas de imitar comportamientos inteligentes humanos.
La dificultad de esta definición está en la palabra inteligente. Nos cuesta definirla para un ser humano, así que para una máquina aún peor. Por eso, para saber si realmente una máquina era inteligente, se ideó el llamado Test de Turing (merece leer el experimento de Alan Turing (1950) Imitation Game) que basicamente dice que si un observador no es capaz de distinguir si está interactuando con un humano o con una máquina entonces podemos decir que esa máquina es inteligente.

Hay dos maneras por las que una máquina puede imitar un comportamiento humano, o la programamos o hacemos que la máquina aprenda por sí sola.
Vamos a ver con un ejemplo la diferencia entre programar y aprender:
Imaginemos que me quiero comprar una casa para después alquilarla maximizando mi inversión. El objetivo entonces sería que mi “máquina” decidiese entre un grupo de posibles compras cúal sería la óptima teniendo en cuenta una serie de variables. Veamos las dos aproximaciones:
Programación tradicional. Lo primero que tengo que hacer es decidir qué variables son las que influyen en el precio de alquiler. Para definir estas variables me tengo que “fiar”, por ejemplo de mi conocimiento del mercado, de mi intuición o de mi experiencia, pero en definitiva de mis valoraciones subjetivas. Imaginemos que las variables que yo identifico que afectan significativamente al precio de alquiler son: superficie, número de habitaciones, localización y si es interior o exterior. Después lo que haré será una tabla con ponderaciones para poder dar una puntuación a cada posible piso a evaluar.
Por lo tanto el orden sería: Diseño y construyo la lógica, introduzco una serie de pisos y obtengo una puntuación y un ranking para poder decidir qué piso comprar. Este proceso lo itero y voy ajustando la lógica hasta que el output cumpla con el diseño inicial.
Características:
Variables limitadas: Las variables que introduzco en el modelo son limitadas por mi conocimiento del problema a modelar. Por ejemplo, no sabré de primeras si la orientación afecta al precio del alquiler y cuánto afecta para poder ponderarla.
Subjetividad: Quiere decir que llevaré al código mis sesgos. Si vivo en Madrid, tenderé a aplicar los pesos pensando que todos los pisos se comportan como en Madrid.
Conocimiento del código. Al final como yo diseño la lógica, conoceré todo el código de programación, y podré saber porqué un piso ha tenido una valoración u otra mirando cómo se ha ejecutado el programa.
Machine Learning. En este caso no vamos a definir ninguna lógica, lo único que necesitamos son los pisos que están en alquiler con sus características (todas y no solo las variables anteriores) y sus precios. Imaginad que podemos coger todos los pisos de Idealista. Lo siguiente es que nuestro algorítmo de machine learning “aprenda” cuales son las variables y los pesos que determinan el precio del alquiler. En este caso la diferencia es que nadie programa las variables ni los pesos sino que es el propio algorítmo el que, analizando muchos casos, identifica que por ejemplo el número de habitaciones es más determinante que la superficie.
Lo interesante de este método es que al poder manejar una cantidad infinita de variables, el algorítmo nos podría decir, por ejemplo que los pisos con mayor rentabilidad de alquiler son aquellos que tienen aire acondicionado, una variable que nosotros ni siquiera habiamos planteado como prioritaria.
Otra ventaja es que el algorítmo puede aprender si introducimos más datos, por ejemplo si añadimos al modelo la distancia a colegios cercanos o restaurantes de moda, puede que el ranking cambie y ahora la cercanía a un colegio pueda tener más relevancia en el precio final del alquiler.
Características
Sin límite de variables: A diferencia del caso anterior, no hay limitación en el uso de variables, cuantos más datos introduzcamos más información para modelar.
Se eliminan los sesgos. Si los sets de datos son representativos y no traen el sesgo, el algorítmo analizará los datos desde un punto de vista estadístico eliminando nuestra subjetividad.
Pérdida de control: En este caso ya no conocemos el códido del algorítmo ya que se ha ido ajustando a medida que lo hemos entrenado. Y es difícil tener la trazabilidad completa del piso recomendado (¿qué utiliza Netflix para recomendarme una película y no otra?)
Las dos formas de resolver el problema son Inteligencia Artificial, pero en la segunda añadimos la capacidad de que la máquina vaya aprendiendo a medida que va recibiendo más información.
Cuando hoy nos referimos a la Inteligencia Artificial estamos añadiendo a la definición original de imitar comportamientos humanos, que además sean capaces de aprender por sí solas.

Machine learning 🧠
Podemos resumir nuestras habilidades inteligentes en: razonar, procesar el lenguaje, hablar, procesar imágenes, manipular objetos y desenvolvernos en el medio.
Estas capacidades están con nosotros a través del aprendizaje que adquirimos por tres vías:
Evolutivo. Millones de años de evolución nos han dado una serie de habilidades codificadas en nuestro ADN como por ejemplo respirar, oler, detectar dolor o placer.
Experiencial. Desde que nacemos estamos continuamente aprendiendo a base de repetir experiencias (como un bebe aprende la gravedad tirando repetidamente cosas al suelo).
Cultural. A través de la sociedad, libros, etc… Esta vía en cierta manera es la que nos diferencia del resto de las especies y nos confiere conocimientos teóricos, conciencia de nosotros mismos, escalas de valores y normas sociales.

A diferencia de los humanos las máquinas poseen una cuarta vía de aprendizaje que son los datos.
Por ejemplo un doctor diagnostica una enfermedad en base a sus conocimientos teóricos, a radiografías y a su experiencia viendo pacientes. Una máquina podría llegar al mismo diagnóstico tan solo analizando miles de pruebas de rayos X.
Este ejemplo nos da una idea de la velocidad de aprendizaje y como la IA cambia completamente las reglas del juego. Lo que a un médico le puede llevar 15 años, una máquina lo puede hacer de forma inmediata si tiene los datos disponibles.
Deep Learning
Una de las técnicas de maching learning son las redes neuronales (veremos en próximos posts qué son). Estas redes van procesando el conocimiento por capas y de ahí el concepto de “deep”.
Imaginemos en nuestro ejemplo de las casas que además de los datos de Idealista (primera capa) introducimos los datos de distancia a colegios cercanos (segunda capa), después a restaurantes (tercera capa) y así sucesivamente hasta que vamos complicando más y más el algorítmo, hasta tal punto que cuando nos salgan los mejores pisos, no sabremos cúal es la combinación óptima de varibles porque se ha perdido en la red neuronal.
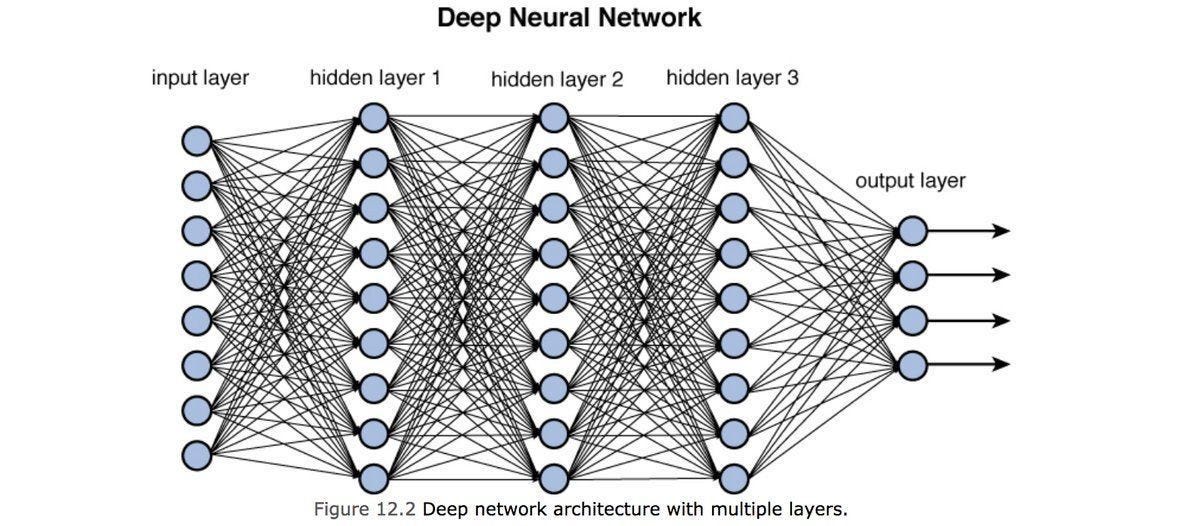
Tipos de aprendizaje 📖
👁 SUPERVISADO: Consiste en entrenar a nuestro algorítmo pasándole inputs y su correspondiente output. Por ejemplo como input miles de imágenes de gatos y como output informarle de que efectivamente todos son gatos. Así la próxima vez que vea un gato, lo identificará como tal. Como curiosidad, se le llama supervisado porque al darle el output en el proceso, estámos influyendo en el aprendizaje.
En nuestro ejemplo de los pisos, para entrenar al algorítmo le pasamos la base de datos de Idealista que contiene los pisos y sus características como input y además su precio de alquiler como output. Con esta información el algorítmo construirá un modelo que utilizará para calcular la inversión óptima. Este tipo de aprendizaje es muy bueno para hacer predicciones y clasificaciones. Es un método costoso porque necesita un set de datos de entrada y salida muy grande y bien clasificado.
🤖 NO SUPERVISADO. En este caso al algorítmo tan solo le estamos pasando datos de entrada sin especificar el output.
Muchas veces no contamos con los datos de entrada tan bien clasificados o no tenemos la respuesta de lo que estamos buscando, por lo tanto el algorítmo lo que va a hacer es trabajar sobre los datos de entrada para establecer patrones, asociaciones o detectar anomalías. Así por ejemplo el aprendizaje no supervisado nos puede recomendar un producto analizando nuestra cesta de la compra. Si estamos comprando pañales y baberos, mediante una asociación a otras cestas de la compra, nos puede sugerir comprar un biberón.
En el tratamiento de imágenes este tipo de aprendizaje hace “clusters” (identifica elementos que pertenecen a una misma estructura) y puede hacer operaciones matemáticas con ellos como por ejemplo unir tu cara con la de un famoso, aislando los elementos o partes del rostro y luego combina el pelo del famoso, tus ojos, los labios del famoso, etc…
Sin embargo hay ocasiones en la que un algorítmo combina los dos aprendizajes. Por ejemplo, si quiero diagnósticar enfermedades a través de radiografías tendré que haber entrenado al algorítmo con muchos diagnósticos pero también el algorítmo por si solo detectará anomalías en la radiografía que asociará a posibles enfermedades.
Tipos de Inteligencia Artificial
Como vemos la IA se puede presentar de innumerables formas. Desde coches autónomos, clasificadores de Spam o diagnóstico de enfermedades por reconocimiento de imágenes. Pero podemos clasificar todas estas aplicaciones en tres grupos según su “nivel de inteligencia”:
IA Débil (Artificial Narrow Intelligence). Se refiere a la IA que es solo capaz de hacer una cosa. Por ejemplo podemos desarrollar un algorítmo para aprender a distinguir perros y gatos pero no sabrá jugar al ajedrez si no le añadimos capacidades para ello.
IA Fuerte (Artificial General Intelligence). También se suele encontrar como “Inteligencia del nivel humano”. Es una inteligencia que puede aprender y realizar más de una tarea. Es mucho más compleja que la IA Débil y todavía no hemos llegado a ella. Un coche autónomo por ejemplo une muchas IA débiles pero todavía no puede aprender otras cosas a menos que se modifiquen sus algorítmos por un humano.
Super Inteligencia (Artificial Superintelligence). Entramos en el terreno casi de la filosofía. Cuando consigamos alcanzar una IA de nivel humano, el siguiente paso será una IA un poco más lista que un humano. Si esa nueva IA se pone a evolucionar, la siguiente IA será todavía más lista… si seguimos así en poco tiempo (exponencial) la IA habrán dejado muy atrás al ser humano.


En próximos posts veremos qué estrategias se están siguiendo para evolucionar la IA débil y conseguir la IA Fuerte o de nivel humano. Hablaremos de redes neuronales, de aplicaciones reales y también veremos qué teorías hay en torno a la superinteligencia, pero ya os adelanto dónde está el debate: ¿Inmortalidad o Extinción? Ahí es nada…
Take Away
En esta infografía está resumido el post:

Si te ha gustado este post, no te olvides de dar al ❤️ y de compartirla por email o redes sociales con otras personas a las que les pueda gustar
Referencias:
The Knowledge Project podcast: Interview Pedro Domingos
Kaizen podcast by Jaime Rodriguez de Santiago
Eliza primer bot conversacional
Muy buen artículo, muy bien explicados términos de los que muchas veces se abusa y se reverencian erróneamente.
Cuando explicas ‘imaginad que tenemos todos los datos de los pisos de idealista’ podrías ampliar en otro artículo hablando de técnicas de web scrapping.
Sin duda la elaboración de algoritmos pasa por tener datos y estas técnicas nos ayudan a conseguirlos.
Podrías reflexionar en un post futuro, algo que ya adelantas, como va a afectar la inclusión de la IA al empleo? Vamos a ver simplemente como se sustituyen puestos de trabajo por estos algoritmos?
Gran artículo! El arte de explicar de forma simple un término complejo ;)